复旦大学NLP(自然语言处理)与大模型研究团队,从20世纪90年代起开始进行自然语言处理、信息检索等方向的研究,是国内最早开展自然语言处理、大规模预训练语言模型、持续学习、价值对齐等相关研究的团队之一,并取得了显著成果。构建了国内首个开源自然语言处理平台 FudanNLP, 发布了高校首个类ChatGPT模型MOSS,以及国内首个中文价值对齐大语言模型MOSS-RLHF。开发了国际上首个大语言模型越狱评测框架Easyjailbreak,以及首个自然语言处理鲁棒性验证平台TextFlint 等。
团队目前包括有教师7名,包括国家级人才2人,省部级人才 4人。近五年主持和承担了国家级科研项目(国家重点研发计划、国家优秀青年科学基金、国家自然科学基金重点项目)6项,省部级科研项目(上海市创新行动计划)5项。与荣耀、华为、百度、联想、科大讯飞等20余家企业进行产学研成果转化与应用。






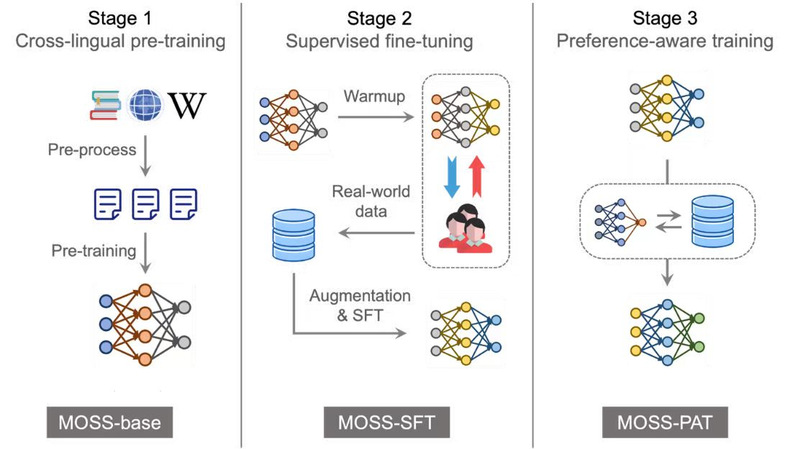
代表性成果:MOSS:通用可信人工智能模型
在低资源情况下突破大模型技术,构建大语言模型MOSS。研究团队在通用人工智能的高效模型设计、训练算法、鲁棒可信等方面取得系列突破,发布了国内首个类ChatGPT大语言模型MOSS。研究团队在大模型的多模态扩展和可信提升方面开展了深入研究,联合发布人工智能治理开放平台“蒲公英”,系统揭示了文本、图像、视频模型的可信问题并创新提出“六维评测框架”,推动解决了全球人工智能治理落地难的问题。研究团队将数据、代码、模型开源,促进了国内大模型技术的蓬勃发展。目前,MOSS已经在金融、医疗、教育等领域取得了广泛的应用,成为国内影响力最大的开源大模型之一。相关成果于2023年在ACL/CVPR/ICML等人工智能领域顶级会议上发表论文50余篇。